

We’re Fly.io and we transmute containers into VMs, running them on our hardware around the world with the power of Firecracker alchemy. We do a lot of stuff with WireGuard, which has become a part of our customer API. This is a quick story about some tricks we played to make WireGuard faster and more scalable for the hundreds of thousands of people who now use it here.
One of many odd decisions we’ve made at Fly.io is how we use WireGuard. It’s not just that we use it in many places where other shops would use HTTPS and REST APIs. We’ve gone a step beyond that: every time you run flyctl, our lovable, sprawling CLI, it conjures a TCP/IP stack out of thin air, with its own IPv6 address, and speaks directly to Fly Machines running on our networks.
There are plusses and minuses to this approach, which we talked about in a blog post a couple years back. Some things, like remote-operated Docker builders, get easier to express (a Fly Machine, as far as flyctl is concerned, might as well be on the same LAN). But everything generally gets trickier to keep running reliably.
It was a decision. We own it.
Anyways, we’ve made some improvements recently, and I’d like to talk about them.
Where we left off
Until a few weeks ago, our gateways ran on a pretty simple system.
- We operate dozens of “gateway” servers around the world, whose sole purpose is to accept incoming WireGuard connections and connect them to the appropriate private networks.
- Any time you run
flyctland it needs to talk to a Fly Machine (to build a container, pop an SSH console, copy files, or proxy to a service you’re running), it spawns or connects to a background agent process. - The first time it runs, the agent generates a new WireGuard peer configuration from our GraphQL API. WireGuard peer configurations are very simple: just a public key and an address to connect to.
- Our API in turn takes that peer configuration and sends it to the appropriate gateway (say,
ord, if you’re near Chicago) via an RPC we send over the NATS messaging system. - On the gateway, a service called
wggwdaccepts that configuration, saves it to a SQLite database, and adds it to the kernel using WireGuard’s Golang libraries.wggwdacknowledges the installation of the peer to the API. - The API replies to your GraphQL request, with the configuration.
- Your
flyctlconnects to the WireGuard peer, which works, because you receiving the configuration means it’s installed on the gateway.
I copy-pasted those last two bullet points from that two-year-old post, because when it works, it does just work reasonably well. (We ultimately did end up defaulting everybody to WireGuard-over-WebSockets, though.)
But if it always worked, we wouldn’t be here, would we?
We ran into two annoying problems:
One: NATS is fast, but doesn’t guarantee delivery. Back in 2022, Fly.io was pretty big on NATS internally. We’ve moved away from it. For instance, our internal flyd API used to be driven by NATS; today, it’s HTTP. Our NATS cluster was losing too many messages to host a reliable API on it. Scaling back our use of NATS made WireGuard gateways better, but still not great.
Two: When flyctl exits, the WireGuard peer it created sticks around on the gateway. Nothing cleans up old peers. After all, you’re likely going to come back tomorrow and deploy a new version of your app, or fly ssh console into it to debug something. Why remove a peer just to re-add it the next day?
Unfortunately, the vast majority of peers are created by flyctl in CI jobs, which don’t have persistent storage and can’t reconnect to the same peer the next run; they generate new peers every time, no matter what.
So, we ended up with a not-reliable-enough provisioning system, and gateways with hundreds of thousands of peers that will never be used again. The high stale peer count made kernel WireGuard operations very slow - especially loading all the peers back into the kernel after a gateway server reboot - as well as some kernel panics.
There had to be
A better way.
Storing bajillions of WireGuard peers is no big challenge for any serious n-tier RDBMS. This isn’t “big data”. The problem we have at Fly.io is that our gateways don’t have serious n-tier RDBMSs. They’re small. Scrappy. They live off the land.
Seriously, though: you could store every WireGuard peer everybody has ever used at Fly.io in a single SQLite database, easily. What you can’t do is store them all in the Linux kernel.
So, at some point, as you push more and more peer configurations to a gateway, you have to start making decisions about which peers you’ll enable in the kernel, and which you won’t.
Wouldn’t it be nice if we just didn’t have this problem? What if, instead of pushing configs to gateways, we had the gateways pull them from our API on demand?
If you did that, peers would only have to be added to the kernel when the client wanted to connect. You could yeet them out of the kernel any time you wanted; the next time the client connected, they’d just get pulled again, and everything would work fine.
The problem you quickly run into to build this design is that Linux kernel WireGuard doesn’t have a feature for installing peers on demand. However:
It is possible to JIT WireGuard peers
The Linux kernel’s interface for configuring WireGuard is Netlink (which is basically a way to create a userland socket to talk to a kernel service). Here’s a summary of it as a C API. Note that there’s no API call to subscribe for “incoming connection attempt” events.
That’s OK! We can just make our own events. WireGuard connection requests are packets, and they’re easily identifiable, so we can efficiently snatch them with a BPF filter and a packet socket.
Most of the time, it’s even easier for us to get the raw WireGuard packets, because our users now default to WebSockets WireGuard (which is just an unauthenticated WebSockets connect that shuttles framed UDP packets to and from an interface on the gateway), so that people who have trouble talking end-to-end in UDP can bring connections up.
We own the daemon code for that, and can just hook the packet receive function to snarf WireGuard packets.
It’s not obvious, but WireGuard doesn’t have notions of “client” or “server”. It’s a pure point-to-point protocol; peers connect to each other when they have traffic to send. The first peer to connect is called the initiator, and the peer it connects to is the responder.
The WireGuard paper is a good read.
For Fly.io, flyctl is typically our initiator, sending a single UDP packet to the gateway, which is the responder. According to the WireGuard paper, this first packet is a handshake initiation. It gets better: the packet type is recorded in a single plaintext byte. So this simple BPF filter catches all the incoming connections: udp and dst port 51820 and udp[8] = 1.
In most other protocols, we’d be done at this point; we’d just scrape the username or whatnot out of the packet, go fetch the matching configuration, and install it in the kernel. With WireGuard, not so fast. WireGuard is based on Trevor Perrin’s Noise Protocol Framework, and Noise goes way out of its way to hide identities during handshakes. To identify incoming requests, we’ll need to run enough Noise cryptography to decrypt the identity.
The code to do this is fussy, but it’s relatively short (about 200 lines). Helpfully, the kernel Netlink interface will give a privileged process the private key for an interface, so the secrets we need to unwrap WireGuard are easy to get. Then it’s just a matter of running the first bit of the Noise handshake. If you’re that kind of nerdy, here’s the code.
At this point, we have the event feed we wanted: the public keys of every user trying to make a WireGuard connection to our gateways. We keep a rate-limited cache in SQLite, and when we see new peers, we’ll make an internal HTTP API request to fetch the matching peer information and install it. This fits nicely into the little daemon that already runs on our gateways to manage WireGuard, and allows us to ruthlessly and recklessly remove stale peers with a cron job.
But wait! There’s more! We bounced this plan off Jason Donenfeld, and he tipped us off on a sneaky feature of the Linux WireGuard Netlink interface.
Jason is the hardest working person in show business.
Our API fetch for new peers is generally not going to be fast enough to respond to the first handshake initiation message a new client sends us. That’s OK; WireGuard is pretty fast about retrying. But we can do better.
When we get an incoming initiation message, we have the 4-tuple address of the desired connection, including the ephemeral source port flyctl is using. We can install the peer as if we’re the initiator, and flyctl is the responder. The Linux kernel will initiate a WireGuard connection back to flyctl. This works; the protocol doesn’t care a whole lot who’s the server and who’s the client. We get new connections established about as fast as they can possibly be installed.
Launch an app in minutes
Speedrun an app onto Fly.io and get your own JIT WireGuard peer ✨
Speedrun →
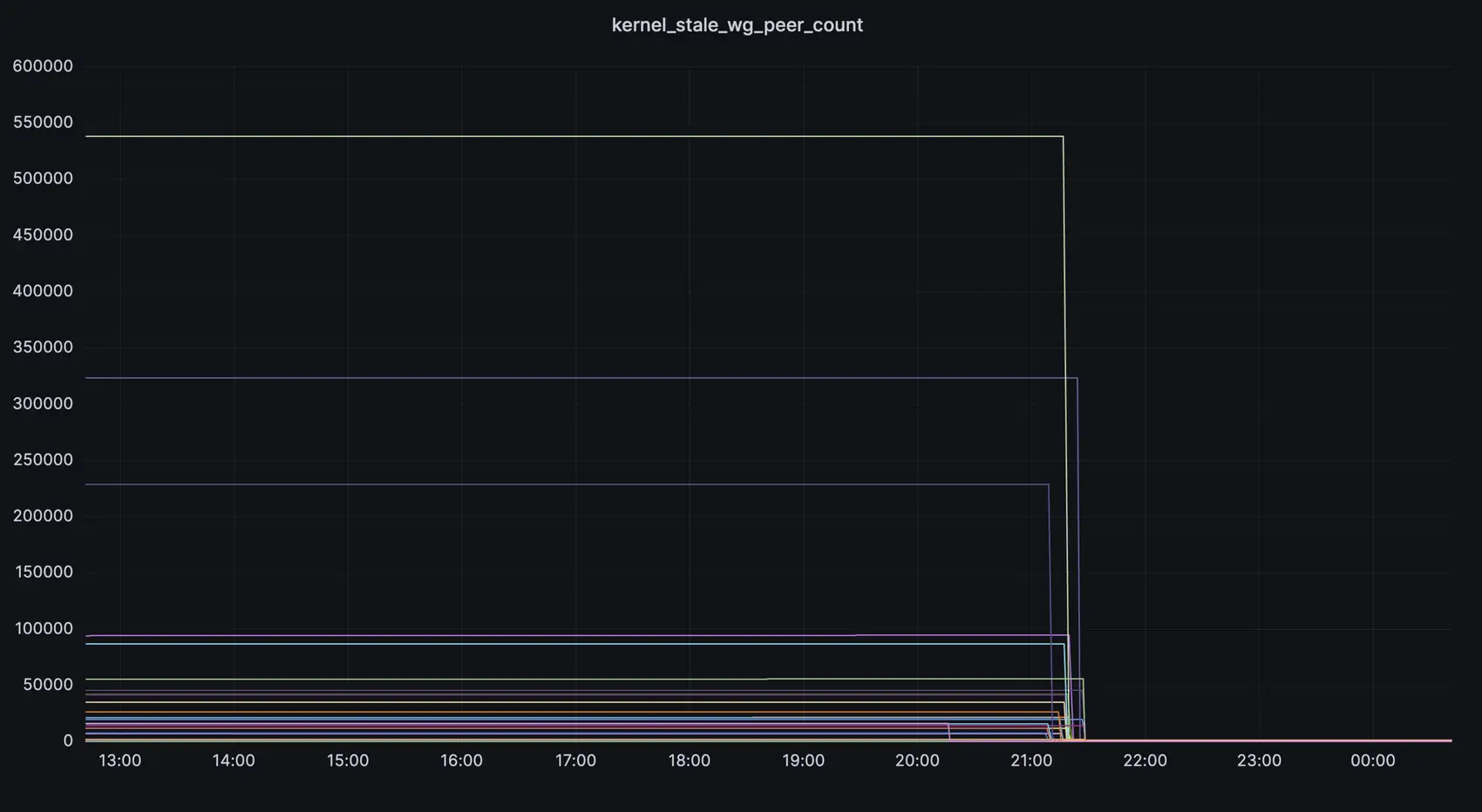
Look at this graph
We’ve been running this in production for a few weeks and we’re feeling pretty happy about it. We went from thousands, or hundreds of thousands, of stale WireGuard peers on a gateway to what rounds to none. Gateways now hold a lot less state, are faster at setting up peers, and can be rebooted without having to wait for many unused peers to be loaded back into the kernel.
I’ll leave you with this happy Grafana chart from the day of the switchover.
Editor’s note: Despite our tearful protests, Lillian has decided to move on from Fly.io to explore new pursuits. We wish her much success and happiness! ✨