


With Fly.io, you can get your app running globally in a matter of minutes, and with LiteFS, you can run SQLite alongside your app! Now we’re introducing LiteFS Cloud: managed backups and point-in-time restores for LiteFS—whether your app is running on Fly.io or anywhere else. Try it out for yourself!
We love SQLite in production, and we’re all about running apps close to users. That’s why we created LiteFS: an open source distributed SQLite database that lives on the same filesystem as your application, and replicates data to all the nodes in your app cluster.
With LiteFS, you get the simplicity, flexibility, and lightning-fast local reads of working with vanilla SQLite, but distributed (so it’s close to your users)! It’s especially great for read-heavy web applications. Learn more about LiteFS in the LiteFS docs and in our blog post introducing LiteFS.
At Fly.io we’ve been using LiteFS internally for a while now, and it’s awesome!
However, something is missing: disaster recovery. Because it’s local to your app, you don’t need to—indeed can't—pay someone to manage your LiteFS cluster, which means no managed backups. Until now, you’ve had to build your own: take regular snapshots, store them somewhere, figure out a retention policy, that sort of thing.
This also means you can only restore from a point in time when you happen to have taken a snapshot, and you likely need to limit how frequently you snapshot for cost reasons. Wouldn’t it be cool if you could have super-frequent reliable backups to restore from, without having to implement it yourself?
Well, that’s why we’re launching, in preview, LiteFS Cloud: backups and restores for LiteFS, managed by Fly.io. It gives you painless and reliable backups, with the equivalent of a snapshot every five minutes (8760 snapshots per month!), whether your database is hosted with us, or anywhere else.
How do I use LiteFS Cloud?
There’s a few steps to get started:
- Upgrade LiteFS to version 0.5.1 or greater
- Create a LiteFS Cloud cluster in the Fly.io dashboard, LiteFS Cloud section
- Make the LiteFS Cloud auth token available to your LiteFS
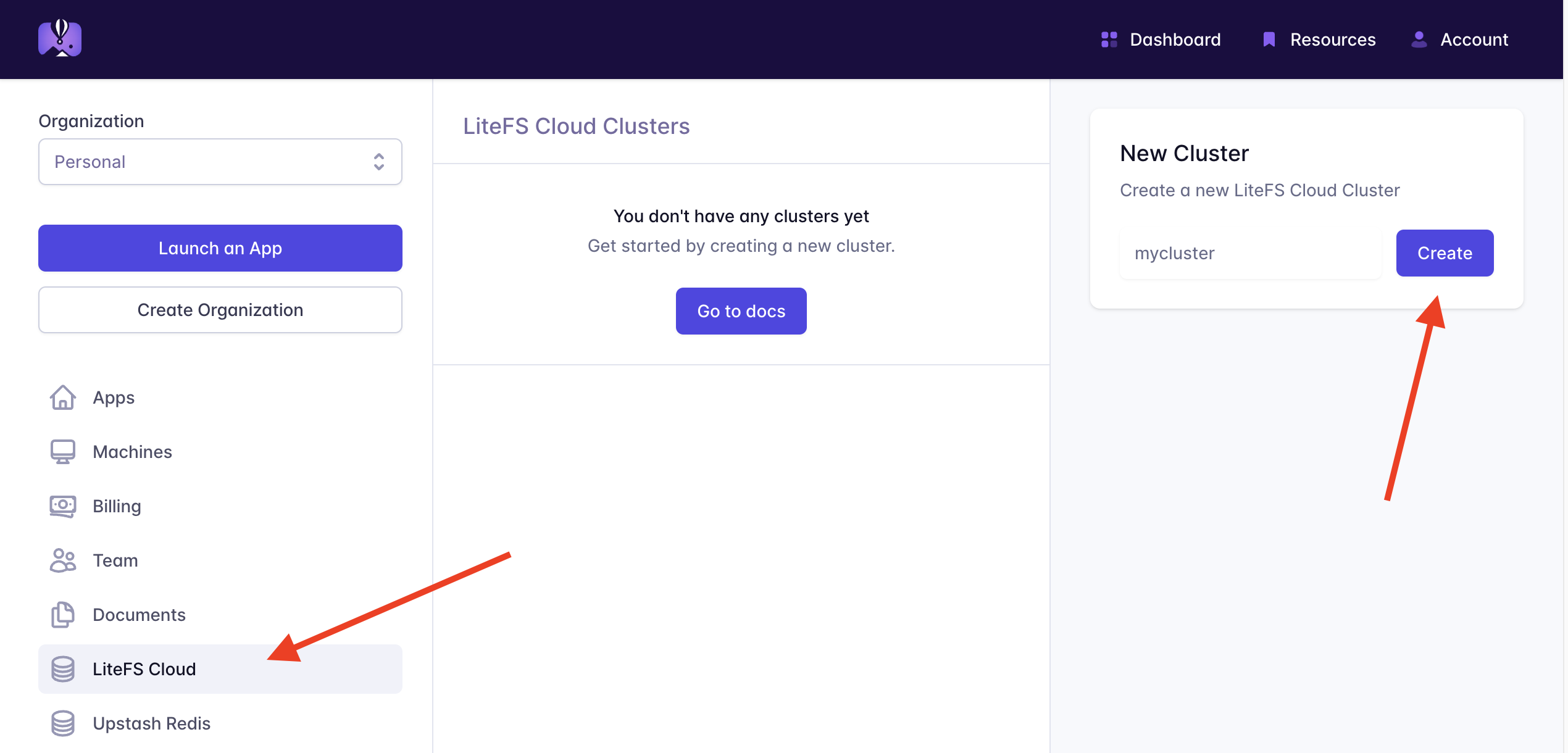
There are some docs here, but that’s literally it. Then your database will start automagically backing up, we’ll manage the backups for you, and you’ll be able to restore your database near instantaneously to any point in time in the last 30 days (with 5 minute granularity).
I want to say that again because I think it’s just wild – you can restore your database to any point in time, with 5 minute granularity. Near instantaneously.
Speaking of restores—you can do those in the dashboard too. You pick a date and time, and we’ll take the most recent snapshot before that timestamp and restore it. This will take a couple of seconds (or less).

We’ll introduce pricing in the coming months, but for now LiteFS Cloud is in preview and is free to use. Please go check it out, and let us know how it goes!
The secret sauce: LTX & compactions
LiteFS is built on a simple file format called Lite Transaction File (LTX) which is designed for fast, flexible replication and recovery in LiteFS itself and in LiteFS Cloud.
But first, let’s start off with what an LTX file represents: a change set of database pages.
When you commit a write transaction in SQLite, it updates one or more fixed-sized blocks called pages. By default, these are 4KB in size. An LTX file is simply a sorted list of these changed pages. Whenever you perform a transaction in SQLite, LiteFS will build an LTX file for that transaction.
The interesting part of LTX is that contiguous sets of LTX files can be merged together into one LTX file. This merge process is called compaction.
For example, let’s say you have 3 transactions in a row that update the following set of pages:
- LTX A: Pages 1, 5, 7
- LTX B: Pages 5, 6
- LTX C: Pages 5, 7
With LTX compaction, you avoid the duplicate work that comes from overwriting the same pages one transaction at a time. Instead, one LTX file for transactions A through C contains the last version of each page, so the pages are stored and updated only once:
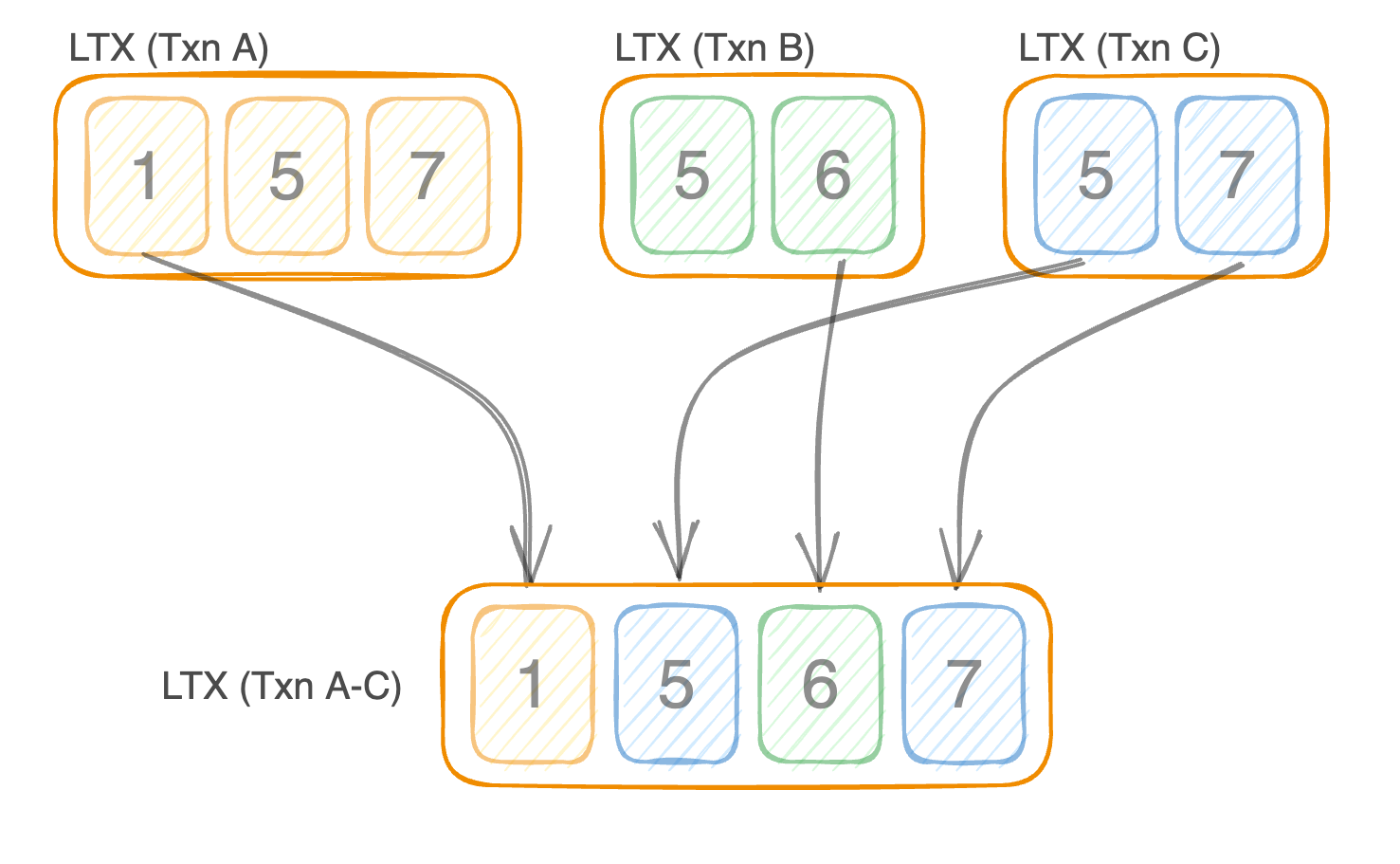
That, in a nutshell, is how a single-level compaction works.
It’s LTX all the way down
Compactions let us take changes for a bunch of transactions and smoosh them down into a single, small file. That’s cool and all but how does that give us fast point-in-time restores? By the magic of multi-level compactions!
Compaction levels are progressively larger time intervals that we roll up transaction data. In the following illustration, you can see that the highest level (L3) starts with a full snapshot of the database. This occurs daily and it’s our starting point during a restore.
Next, we have an hourly compaction level called L2 so there will be an LTX file with page changes between midnight and 1am, and then another file for 1am to 2am, etc. Below that is L1 which holds 5-minute intervals of data.
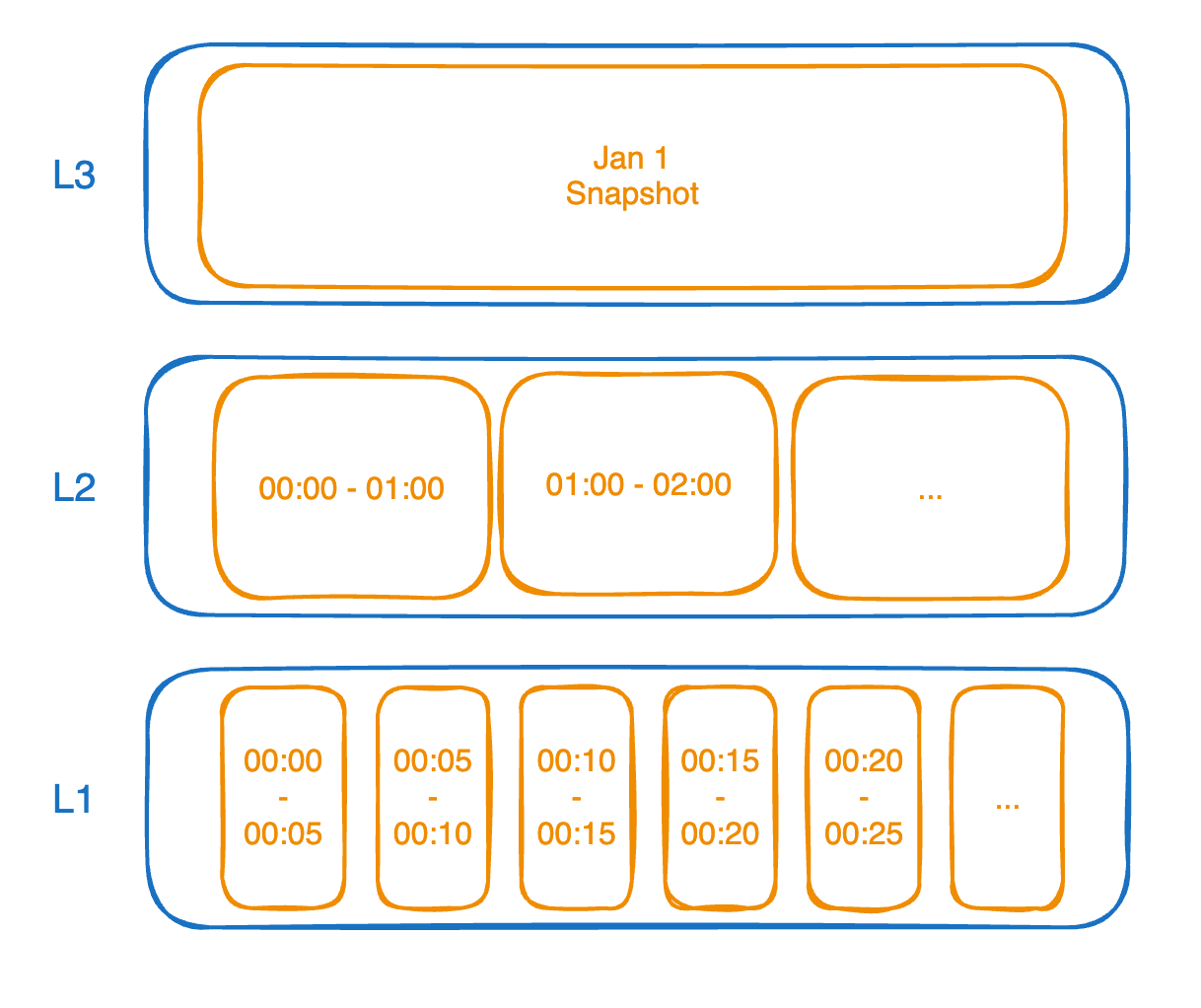
When a restore is requested for a specific timestamp, we can determine a minimal set of LTX files to replay. For example, if we restored to January 10th at 8:15am we would grab the following files:
- Start with the snapshot for January 10th.
- Fetch the eight hourly LTX files from midnight to 8am.
- Fetch the three 5-minute interval LTX files from 8:00am to 8:15am.
Since LTX files are sorted by page number, we can perform a streaming merge of these twelve files and end up with the state of the database at the given timestamp.
Department of Redundancy Department
One of the primary goals of LiteFS is to be simple to use. However, that’s not an easy goal for a distributed database when our industry is moving more and more towards highly dynamic and ephemeral infrastructure. Traditional consensus algorithms require stable membership and adjusting the member set can be complicated.
With LiteFS, we chose to use async replication as the primary mode of operation. This has some trade-offs in durability guarantees but it makes the cluster much simpler to operate. LiteFS Cloud alleviates many of these trade-offs of async replication by writing data out to high-durability, high-availability object storage—for now, we’re using S3.
However, we don’t write every individual LTX file to object storage immediately. The latency is too high and it’s not cost effective when you write a lot of transactions. Instead, the LiteFS primary node will batch up its changes every second and send a single, compacted LTX file to LiteFS Cloud. Once there, LiteFS Cloud will batch these 1-second files together and flush them to storage periodically.
We track the ID of the latest transaction that’s been flushed, and we call this the “high water mark” or HWM. This transaction ID is propagated back down to the nodes of the LiteFS cluster so we can ensure that the transaction file is not removed from any node until it is safely persisted in object storage. With this approach, we have multiple layers of redundancy in case your LiteFS cluster can’t communicate with LiteFS Cloud or if we can’t communicate with S3.
What’s next for LiteFS Cloud?
We have a small team dedicated to LiteFS Cloud, and we’re chugging away at new exciting features! Right now, LiteFS Cloud is really just backups and restores, but we are working on a lot of other cool stuff:
- Upload your database in the Fly.io dashboard. This way you don’t have to worry about figuring out how to initialize your database when you first deploy it, just upload the database in the dashboard and LiteFS will pull it from LiteFS Cloud.
- Download a point-in-time snapshot of your database from the Fly.io dashboard. You can use this to spin up a local dev env (with production data), do some local analysis, etc.
- Clone your LiteFS Cloud cluster to a new cluster, which you could use for a staging environment (or on-demand test environments for your CI pipelines) with real data.
- Features to support apps that run on serverless platforms like Vercel, Google Cloud Run, Deno, and more. We’ll need to develop a number of different features for this, stay tuned for more information in the coming weeks!
We’re really excited about the future of LiteFS Cloud, so we wanted to share what we’re thinking. We’d also love to hear any feedback you have about these ideas that might inform our work.